

 天天爆殺
天天爆殺  今日66折
今日66折 

































從Hey、Siri、OK Google開始,我們早已習慣用語音來控制設備,語音輸入法取代鍵盤,Google幫你朗讀文章,你一定很好奇這些語音系統是如何建造出來的。
本書以Kaldi為主,完整介紹Librispeech等資料處理,並且完整說明了三音素架構。
語音模型方面:完整介紹語言模型、n元模型。
特徵工程方面:完整介紹包括對齊、Transition模型、GMM模型等。
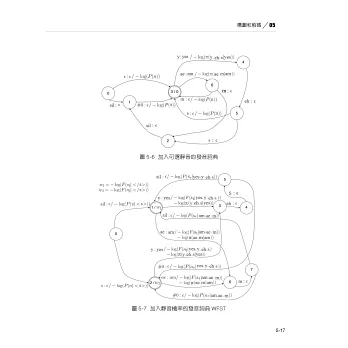
構圖及解碼方面:完整介紹OpenFST、WFST等技術。
深度學習建模方面:完整介紹nnet、nnet2、nnet3。
大家最常用的語音搜尋、語音喚醒也有完整的實作介紹。類似人臉辨識的「人聲」辨識,也用PLDA、i-vector、x-vector等技術實作,最近當紅的語言辨識也沒錯過,可說是深入語音工程的最佳手冊。
好評來襲
顏永紅 中國科學院語言聲學與內容了解重點實驗室主任
Kaldi 開放原始碼軟體對推動語音技術研究和產品落地做出了不可磨滅的貢獻,本書作者是工作在語音研究和產業前端的青年才俊,他們以第一手經驗詳細說明了如何運用該軟體建置實際系統,這對初學者迅速掌握相關知識和技能是非常有益的。
俞凱 上海交通大學智慧語音技術實驗室主任,思必馳聯合創始人、首席科學家
我和Dan Povey 博士十幾年前在劍橋大學共事時,使用的是早期最著名的語音辨識開放原始碼軟體之一:HTK。雖然後來Kaldi 因其靈活的設計、開放的協定和豐富的功能而如日中天,卻一直在系統教學方面遠遠落後於HTK。本書從理論和實作的角度對Kaldi 進行了完整呈現,不僅有其實用價值,也為「知其所以然」列出了很好的註釋,相信必然會對Kaldi 的傳播和語音辨識技術的發展造成積極的促進作用。
崔寶秋 小米集團副總裁、集團技術委員會主席
Kaldi 是開放原始碼語音技術的典範,是大專院校同學們入門語音的啟發工具,也是人們快速提升語音技術的捷徑。它消除了大家因為長期沉浸在語音教科書和論文裡而產生的「手癢」,給人們帶來快速上手實作、快速感受語音資料之美的快樂。本書作者們都有豐富的工業界(包含小米)實戰經驗和深厚的學術累積,他們把這些經驗和累積無私地貢獻出來,也真正表現了開放原始碼的共用精神。擁抱開放原始碼是小米的工程文化,衷心希望Kaldi 及其社區在Daniel Povey 博士的主管下不斷茁壯成長、領導語音技術的發展。
張錦懋 美團首席科學家、基礎研發平台負責人
Kaldi 的誕生使得語音辨識領域的研究和創新成本都顯著降低,讓整個企業都獲益匪淺。這本書的幾位作者非常全面地介紹了Kaldi 的功能,包含資料處理、聲學模型、解碼器等相關的工具,同時對相關理論也進行了詳細的說明,讓讀者不僅學會使用Kaldi,而且能夠了解為什麼這麼使用。
雷欣 出門問問首席技術官
Kaldi 相比於經典的HTK 工具套件進行了極大的最佳化,譬如C++ 的採用、以WFST 為基礎的靜態解碼器、達到state-of-the-art 效能的recipe 指令稿等。這些優勢使得Kaldi 開放原始碼函數庫獲得迅速的發展,相當大地降低了語音技術的門檻,使得像出門問問這樣的語音創業公司能在短時間內開發出一流的語音技術產品。相比於經典的HTK Book,Kaldi 在文件方面則顯得落後很多。本書的作者們都是Kaldi 社區的活躍開發者,對Kaldi 及語音技術具有深刻的了解,他們的努力使得中國的語音技術同好們有了一本入門和加強的參考書,必將進一步推動語音技術的普及。
鄒月嫻 北京大學教授、博士生導師,深圳市人工智慧學會專家委主任
我在北京大學深圳研究所學生院開展教學和科學研究工作十四個整年頭,其間為電腦應用技術專業的學生主講「機器學習與模式識別」課程,帶領一群優秀的研究所學生開展機器聽覺技術研究。我們的教學和研究得益於許多的開放原始碼專案,深切體會到Kaldi 作為主流的語音辨識開放原始碼工具對同學們的幫助。Kaldi 秉承其開放原始碼社區的傳統特性,支援主流的機器學習架構和演算法,受到許多業界和學界開發者的支援。我相信本書的作者們正是秉承這樣的精神,以實際行動支援Kaldi 開放原始碼社區。這本書不僅介紹了語音技術的發展簡史、Kaldi 的發展歷史,也涵蓋了最新的以深度學習為基礎的語音技術主流架構和語音辨識應用實作案例,所呈現的內容和提供的實戰技巧接近產業需求,該書的出版將有益於學子們更加快速地了解主流的語音技術並迅速開展程式設計實作,推動語音技術進步和應用的發展。
李嵐 中軟國際教育科技集團人工智慧研究院執行院長
人工智慧技術在近年被確立為國家戰略後,大專院校和企業間深度合作,在人工智慧的人才培養上形成了一致看法,即實作是學校和學生的一致需求。從產業界的實際發展來看,隨著人工智慧技術應用領域的擴充,「聽」這一感知領域,已經是迫切需要得以提升和發展的。企業專家,特別是實際應用領域的專家聯合推動的企業資料和技術開放原始碼,為這個領域的人才培養做出了貢獻。而如何讓更多的老師和學生們了解語音領域的發展現狀及學習路徑,需要和本書的作者們一樣,分享自己的了解和系統整理。我們也將在後續工作中,將本書作為我們的教材之一,希望能推動語音領域人才的培養。





 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來