

 天天爆殺
天天爆殺  今日66折
今日66折 

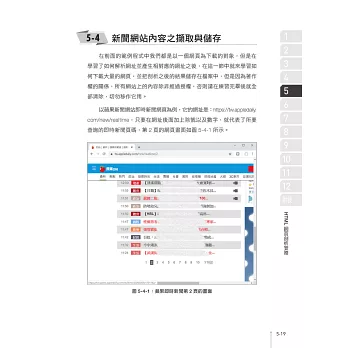



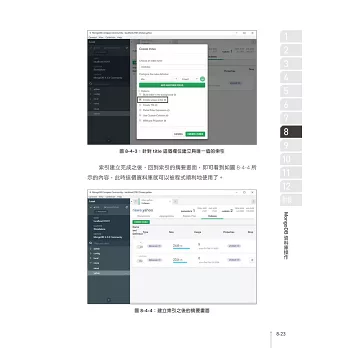












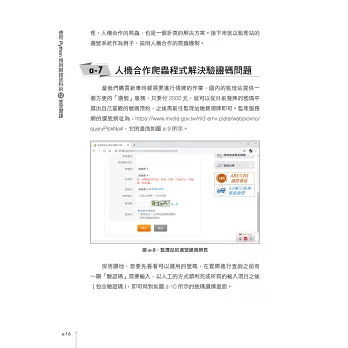
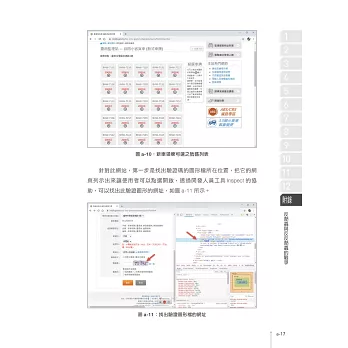

















網路爬蟲是AI範疇中,
取得資料與儲存的一項重要技能,
而Python是爬蟲過程中相當好用的工具
全書以簡單的Python程式為主軸,讓您可以輕鬆學會如何利用Python的模組擷取公開的網站資料、網頁內容,並建立自己的自動化爬蟲程式,增進您在網路上搜刮資料的能力與效率,是已具有Python基礎的學習者最佳的爬蟲入門工具書。
在本書中我們將學會使用以下的Python開發環境、模組及框架:
Thonny Jupyter Notebook requests
json csv re
xlrd BeautifulSoup Selenium
sqlite3 mysql pymongo
pyinstaller Scrapy pyautogui
並學習如何擷取以下的幾種網站:
☑大學網站的焦點新聞頁面 ☑政府公開資訊網站
☑即時新聞網站標題、內容、圖片 ☑汽車網站之車款資訊及二手車在庫資訊
☑銀行網站之匯率資料擷取 ☑中央氣象局之氣溫觀測資訊
☑Ptt八卦版年齡宣告按鈕及Ptt討論區貼文擷取 ☑網路書店暢銷書排行榜
☑股市網站財經新聞 ☑線上購物網站產品資訊
☑名言佳句範例網站 ☑台灣證券交易所股票資訊
☑Dcard梗圖下載 ☑台灣運彩官網資訊
☑Mobile01討論區貼文
本書特色
✪了解網站、網頁、瀏覽器間的關係,認識爬蟲程式
✪了解網路上格式HTML/CSV/JSON/XLSX
✪使用requests模組取得網路上的資料
✪擷取及解析JSON及CSV格式資料檔案
✪利用Regular Expression及BeautifulSoup模組剖析網頁資料
✪活用Chrome開發人員工具找出網頁中特定資料的CSS選擇器內容
✪使用Selenium自動化工具擷取動態網頁
✪把擷取的資料儲存到MySQL及MongoDB資料庫
✪利用排程器做到自動化資料擷取及通知的功能
✪透過Scrapy框架建立爬蟲程式,大量搜刮資料







 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來