

 天天爆殺
天天爆殺  今日66折
今日66折 





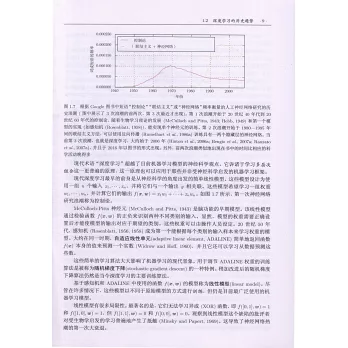















由全球知名的三位專家Ian Goodfellow、Yoshua Bengio 和Aaron Courville撰寫,是深度學習領域奠基性的經典教材。
全書包括3個部分:第1部分介紹基本的數學工具和機器學習的概念,它們是深度學習的預備 知識;第2部分系統深入地講解現今已成熟的深度學習方法和技術;第3部分討論某些具有前瞻性的方向和想法,它們被公認為是深度學習未來的研究重點。
《深度學習》適合各類讀者閱讀,包括相關專業的大學生或研究生,以及不具有機器學習或統計背景、但是想要快速補充深度學習知識,以便在實際產品或平台中應用的軟件工程師。
Ian Good fellow,谷歌公司(Google) 的研究科學家,2014 年蒙特利爾大學機器學習博士。他的研究興趣涵蓋大多數深度學習主題,特別是生成模型以及機器學習的安全和隱私。Ian Good fellow 在研究對抗樣本方面是一位有影響力的早期研究者,他發明了生成式對抗網絡,在深度學習領域貢獻卓越。
Yoshua Bengio,蒙特利爾大學計算機科學與運籌學系(DIRO) 的教授,蒙特利爾學習算法研究所(MILA) 的負責人,CIFAR 項目的共同負責人,加拿大統計學習算法研究主席。Yoshua Bengio 的主要研究目標是了解產生智力的學習原則。他還教授「機器學習」研究生課程(IFT6266),並培養了一大批研究生和博士后。
Aaron Courville,蒙特利爾大學計算機科學與運籌學系的助理教授,也是LISA 實驗室的成員。目前他的研究興趣集中在發展深度學習模型和方法,特別是開發概率模型和新穎的推斷方法。Aaron Courville 主要專注於計算機視覺應用,在其他領域,如自然語言處理、音頻信號處理、語音理解和其他AI 相關任務方面也有所研究。








 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來