序
GPT 的啟示
ChatGPT 石破天驚,GPT-4 的問世又引發了進一步的轟動,GPT-5 即將到來⋯⋯它們的影響遠遠超出了大家的預期和想像。有觀點認為,ChatGPT 是通用人工智慧的Singularity(奇點)。無獨有偶,2022 年,微軟發佈了一篇論文Singularity: Planet-Scale, Preemptive and Elastic Scheduling of AI Workloads,介紹其全域分散式排程服務,作者包括Azure 的CTO Mark Russinovich。而Azure與OpenAI 合作,重新設計了超級電腦,在Azure 雲端上為OpenAI 訓練超大規模的模型。該論文將Azure 的全域分散式排程服務命名為Singularity,可見其深意。
GPT-3 模型的參數量是1750 億個,研發這個規模的大型模型,是一個極其複雜的系統工程,涵蓋了演算法、算力、網路、儲存、巨量資料、框架、基礎設施等多個領域。微軟2020 年發佈的資訊稱,其計畫為OpenAI 開發的專用超級電腦包括28.5 萬個CPU、1 萬個GPU。市場調查機構TrendForce 的報告則指出,ChatGPT 需要3 萬個GPU。在OpenAI 官網和報告中都提到,GPT-4 專案的重點之一是開發一套可預測、可擴展的深度學習堆疊和基礎設施(Infrastructure)。與之對應的是,在OpenAI 研發團隊的6 個小組中,有5 個小組的工作涉及AI工程和基礎設施。
OpenAI 沒有提供GPT-4 的架構(包括模型大小)、硬體、資料集、訓練方法等內容,這非常令人遺憾,但是我們可以從微軟發佈的論文入手,來研究GPT-4 這座冰山在水下的那些深層技術堆疊。從論文可以看出,GPT 使用的底層技術並沒有那麼「新」,而是在現有技術基礎之上進行的深度打磨,並從不同角度對現有技術進行了拓展,做到工程上的極致。比如Singularity 在GPU 排程方面,就有阿里巴巴AntMan 的影子。再比如Singularity 從系統角度出發,使用CRIU 完成任務先佔、遷移的同時,也巧妙解決了彈性訓練的精度一致性問題。
AI 的黃金時代可能才剛剛開啟,各行各業的生產力革命也會相繼產生。誠然,OpenAI 已經佔據了領先位置,但是接下來的AI 賽道會風起雲湧,企業勢必會在其中扮演極其重要的角色,也會在深度學習堆疊和基礎設施領域奮起直追。然而,「彎道超車」需要建立在技術沉澱和產品實力之上,我們只有切實地紮根於現有的分散式機器學習技術系統,並進行深耕,才能為更好的創新和發展打下基礎。大家都已在路上,沒有人直接掌握著通向未來的密碼,但面對不可阻擋的深層次的資訊革命和無限的發展機遇,我們必須有所準備。
複雜模型的挑戰
為了降低在大型態資料集上訓練大型模型的計算成本,研究人員早已轉向使用分散式運算系統結構(在此系統結構中,許多機器協作執行機器學習方法)。人們建立了演算法和系統,以便在多個CPU 或GPU 上並行化機器學習(Machine Learning,ML)程式(多裝置並行),或在網路上的多個計算節點並行化機器學習訓練(分散式並行)。這些軟體系統利用最大似然理論的特性來實現加速,並隨著裝置數量的增加而擴展。理想情況下,這樣的並行化機器學習系統可以透過減少訓練時間來實現大型模型在大型態資料集上的並行化,從而實現更快的開發或研究迭代。
然而,隨著機器學習模型在結構上變得更加複雜,對大多數機器學習研究人員和開發人員來說,即使使用TensorFlow、PyTorch、Horovod、Megatron、DeepSpeed 等工具,撰寫高效的並行化機器學習程式仍然是一項艱鉅的任務,使用者需要考慮的因素太多,比如:
• 系統方面。現有系統大多是圍繞單一並行化技術或最佳化方案來建構的,對組合多種策略的探索不足,比如不能完全支持各種混合並行。
• 性能方面。不同並行化策略在面對不同的運算元時,性能差異明顯。有些框架未考慮叢集物理拓撲(叢集之中各個裝置的算力、記憶體、頻寬有時會存在層級的差距),使用者需要依據模型特點和叢集網路拓撲來選擇或調整並行化策略。
• 易用性方面。很多系統需要開發人員改寫現有模型,進行手動控制,比如添加通訊基本操作,控制管線等。不同框架之間彼此割裂,難以在不同並行策略之間遷移。
• 可用性方面。隨著訓練規模擴大,硬體薄弱或設計原因會導致單點故障機率隨之增加,如何解決這些痛點是個嚴重問題。
總之,在將分散式並行訓練系統應用於複雜模型時,「開箱即用」通常會導致低於預期的性能,求解最佳並行策略成為一個複雜度極高的問題。為了解決這個問題,研究人員需要對分散式系統、程式設計模型、機器學習理論及其複雜的相互作用有深入的了解。
本書是筆者在分散式機器學習領域學習和應用過程中的總結和思考,期望能造成拋磚引玉的作用,帶領大家走入/ 熟悉分散式機器學習這個領域。
本書的內容組織
PyTorch 是大家最常用的深度學習框架之一,學好PyTorch 可以很容易地進入分散式機器學習領域,所以全書以PyTorch 為綱進行穿插講解,從系統和實踐的角度對分散式機器學習進行整理。本書架構如下。
第1 篇 分散式基礎
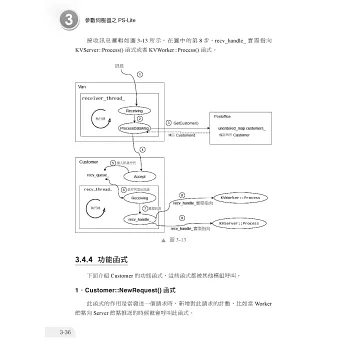
本篇首先介紹了分散式機器學習的基本概念、基礎設施,以及機器學習並行化的技術、框架和軟體系統,然後對集合通訊和參數伺服器PS-Lite 進行了介紹。
第2 篇 資料並行
資料並行(Data Parallelism)是深度學習中最常見的技術。資料並行的目的是解決計算牆,將計算負載切分到多張卡上。資料並行具有幾個明顯的優勢,包括計算效率高和工作量小,這使得它在高計算通訊比的模型上運行良好。本篇以PyTorch 和Horovod 為主對資料並行進行分析。
第3 篇 管線並行(Pipeline Parallelism)
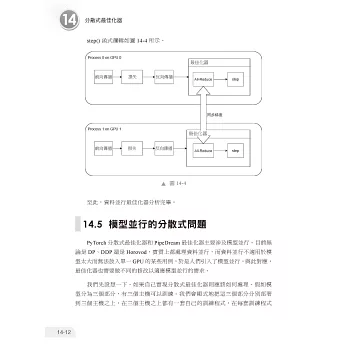
當一個節點無法存下整個神經網路模型時,就需要對模型進行切分,讓不同裝置負責計算圖的不同部分,這就是模型並行(Model Parallelism)。從計算圖角度看,模型並行主要有兩種切分方式:層內切分和層間切分,分別對應了層內模型並行和層間模型並行這兩種並行方式。業界把這兩種並行方式分別叫作張量模型並行(簡稱為張量並行,即Tensor Parallelism)和管線模型並行(簡稱為管線並行,即Pipeline Parallelism)。
張量模型並行可以把較大參數切分到多個裝置,但是對通訊要求較高,計算效率較低,不適合超大模型。在管線模型並行中,除了對模型進行層間切分外,還引入了額外的管線來隱藏通訊時間、充分利用裝置算力,從而提高了計算效率,更合適超大模型。
因為管線並行的獨特性和重要性,所以對這部分內容單獨介紹。本篇以GPipe、PyTorch、PipeDream 為例來分析管線並行。
第4 篇 模型並行
目前已有的深度學習框架大都提供了對資料並行的原生支援,雖然對模型並行的支援還不完善,但是各個框架都有自己的特色,可以說百花齊放,百家爭鳴。本篇介紹模型並行,首先會對NVIDIA Megatron 進行分析,講解如何進行層內分割模型並行,然後學習PyTorch 如何支援模型並行。
第5 篇 TensorFlow 分散式
本篇學習TensorFlow 如何進行分散式訓練。迄今為止,在分散式機器學習這一系列分析之中,我們大多以PyTorch 為綱,結合其他框架/ 庫來穿插完成。但是缺少了TensorFlow 就會覺得整個世界(系列)都是不完美的,不僅因為TensorFlow 本身有很強大的影響力,更因為TensorFlow 分散式博大精深,特色鮮明,對技術同好來說是一個巨大寶藏。
本書適合的讀者
本書讀者群包括:
• 機器學習領域內實際遇到巨量資料、分散式問題的人,不但可以參考具體解決方案,也可以學習各種技術背後的理念、設計哲學和發展過程。
• 機器學習領域的新人,可以按圖索驥,了解各種框架如何使用。
• 其他領域(尤其是巨量資料領域和雲端運算領域)想轉入機器學習領域的工程師。
• 有好奇心,喜歡研究框架背後機制的學生,本書也適合作為機器學習相關課程的參考書籍。
如何閱讀本書
本書源自筆者的部落格文章,整體來說是按照專案解決方案進行組織的,每一篇都是關於某一特定主題的方案集合。大多數方案自成一體,每個獨立章節中的內容都是按照循序漸進的方式來組織的。
行文
• 本書以神經網路為主,兼顧傳統機器學習,所以舉例往往以深度學習為主。
• 因為本書內容來源於多種框架/ 論文,這些來源都有自己完整的系統結構和邏輯,所以本書會存在某一個概念或問題以不同角度在前後幾章都論述的情況。
• 解析時會刪除非主體程式,比如異常處理程式、某些分支的非關鍵程式、輸入的檢測程式等。也會省略不重要的函式參數。
• 一般來說,對於類別定義只會舉出其主要成員變數,某些重要成員函式會在使用時再介紹。
• 本書在描述類之間關係和函式呼叫流程上使用了UML類別圖和序列圖,但是因為UML 規範過於繁雜,所以本書沒有完全遵循其規範。對於圖例,如果某圖只有細實線,則可以根據箭頭區分是呼叫關係還是資料結構之間的關係。如果某圖存在多種線條,則細實線表示資料結構之間的關係,粗實線表示呼叫流程,虛線表示資料流程,虛線框表示清單資料結構。
版本
各個框架發展很快,在本書寫作過程中,筆者往往會針對某一個框架的多個版本進行研讀,具體框架版本對應如下。
• PyTorch:主要參考版本是1.9.0。
• TensorFlow:主要參考版本是2.6.2。
• PS-Lite:master 版本。
• Megatron:主要參考版本是2.5。
• GPipe:master 版本。
• PipeDream:master 版本。
• torchgpipe:主要參考版本是0.0.7。
• Horovod:主要參考版本是0.22.1。
深入
在本書(包括部落格)的寫作過程中,筆者參考和學習了大量論文、部落格和講座影片,在此對這些作者表示深深的感謝。具體參考資料和連結請參照本書官網連結。如果讀者想繼續深入研究,除論文、文件、原作者部落格和原始程式之外,筆者有以下建議:
• PyTorch: 推薦OpenMMLab@ 知乎,Gemfield@ 知乎。Gemfield 是PyTorch 的萬花筒。
• TensorFlow: 推薦西門宇少(DeepLearningStack@cnblogs)、劉光聰(horance-liu@github)。西門宇少兼顧深度、廣度和業界前端。劉光聰的電子書《TensorFlow 核心剖析》是同領域最佳,本書參考頗多。
• Megatron:推薦迷途小書僮@ 知乎,其對Megatron 有非常精彩的解讀。
• 整體:推薦張昊@ 知乎、OneFlow@ 知乎,既高屋建瓴,又緊扣實際。
• 劉鐵岩、陳薇、王太峰、高飛的《分散式機器學習:演算法、理論與實踐》非常經典,強烈推薦。
致謝
首先,感謝我生命中遇到的各位良師:許玉娣老師、劉健老師、鄒豔聘老師、王鳳珍老師、欒錫寶老師、王金海老師、童若鋒老師、唐敏老師、趙慧芳老師,董金祥老師⋯⋯師恩難忘。童若鋒老師是我讀本科時的班主任,又和唐敏老師一起在我攻讀碩士學位期間對我進行悉心指導。那時童老師和唐老師剛剛博士畢業,兩位老師亦師亦友,他們的言傳身教讓我受益終生。
感謝我的編輯黃愛萍在本書出版過程中給我的幫助。對我來說,寫部落格是快樂的,因為我喜歡技術,喜歡研究事物背後的機制。整理出書則是痛苦的,其難度遠遠超出了預期,從整理到完稿用了一年多時間。沒有編輯的理解和支持,這本書很難問世。另外,因為篇幅所限,筆者部落格中的很多內容(比如DeepSpeed、彈性訓練、通訊最佳化、資料處理等)未能在書中表現,甚是遺憾。
感謝童老師、孫力哥、媛媛姐、文峰同學,以及袁進輝、李永(九豐)兩位大神在百忙之中為本書寫推薦語,謝謝你們的鼓勵和支持。
最後,特別感謝我的愛人和孩子們,因為寫部落格和整理書稿,我犧牲了大量本應該陪伴她們的時間,謝謝她們給我的支持和包容。也感謝我的父母和岳父母幫我們照顧孩子,讓我能夠長時間在電腦前面忙忙碌碌。
由於筆者水平和精力都有限,而且本書的內容較多、牽涉的技術較廣,謬誤和疏漏之處在所難免,很多技術點設計的細節描述得不夠詳盡,懇請廣大技術專家和讀者指正。可以將意見和建議發送到我的個人電子郵件RossiLH@163.com,或透過部落格園、CSDN、掘金或微信公眾號搜索「羅西的思考」與我進行交流和資料獲取。我也將密切追蹤分散式機器學習技術的發展,吸取大家意見,適時撰寫本書的升級版本。
柳浩


 天天爆殺
天天爆殺  今日66折
今日66折 









































 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來 博客來
博客來